关于 posthoc_nemenyi_friedman() 函数的一点思考
前言
Scikit-posthocs 这个库提供了许多 Post-hoc (后续检验) 的函数,Tukey Post-hoc, Nemenyi Post-hoc 等常见后续测试在这个库里都有相对应的实现,使用起来较为方便。
最近做的作业中要求使用 Friedman 测试和 Nemenyi 后续测试,来检验三个分类算法的精度是否有较大差异。于是博主使用了 Scikit-posthocs 的 posthoc_nemenyi_friedman() 函数。但在使用过程中我发现这个函数的返回值和我预想中的不一样,它返回了一个所谓的 P-values 矩阵,这个矩阵长这样:
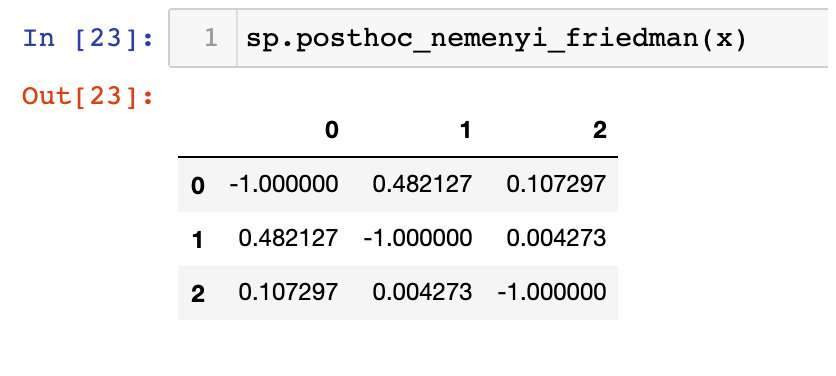
盲猜矩阵的每个 P-value 是用来和 𝛼 做比较的,但是比较的原则是怎样的呢?这个比较的结果和 Nemenyi 测试结果是怎样关联的呢?
于是查看了一下这个函数的官方文档,然而文档只说明了函数用法,并没有详细说明函数内部操作的具体流程,无法解除我的疑惑。好在这个库是开源的,于是博主研究了一下这个函数的源码.
经过博主的一系列研究,最终发现
这个矩阵中的 P-value 由算法两两比较而产生,用来与 α 做比较,如果 P-value > α,则被比较的两个算法没有明显差异,如果 P-value < α,则被比较的两个算法有明显差异 (Reject H0).
下面是研究过程:
Nemenyi 测试
在解释这个函数的流程之前,我们必须先熟稔 Nemenyi 测试的流程
根据西瓜书上的说明,Friedman 测试结果如果表明 “算法性能显著不同”,则需进行 Nemenyi 后续测试。书上所描述的 Nemenyi 测试流程是这样的:
根据公式计算 Critical Difference (CD),q⍺ 可查表获得
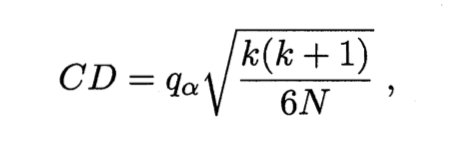
将两个算法的平均序值的差 (Average Rank Difference, ARD) 和 CD 进行比较,如果 ARD > CD,则两个算法的性能有明显差异。
函数源码解释
由上述 Nemenyi 测试的解释可得,在西瓜书中, Nemenyi 测试的核心在于计算 CD, 并将其与 ARD 进行比较。然而研究源码之后,博主发现posthoc_nemenyi_friedman()的思路和上述流程迥然不同,十分清奇,值得一看。下面是该函数作者的思路:
在 CD 公式中,由于 k 和 N 是恒定的,因此可知 q⍺ 的值决定了 CD 的值,CD 与 q⍺ 存在函数映射
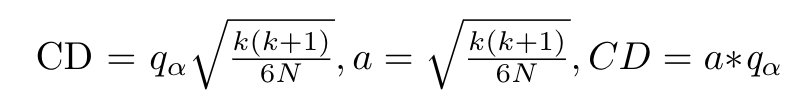
由于 ARD 和 CD 是可比较的,意味着 ARD 可化成与 CD 相同的形式。
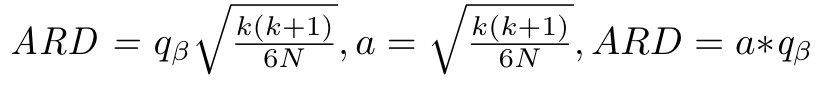
对等式做变换得
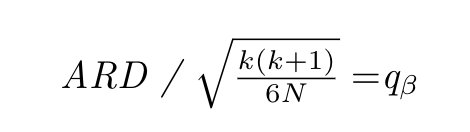
等式的左边可通过计算得出,将算出的 qβ 值代入
自由度 = infinity,样本数 = k的学生化极差分布(Studentized Range),即可得到 β,β 即为函数返回的 P-value,用于和 α 进行比较
西瓜书中解释道 “q⍺ 是 Tukey 分布的临界值,在 R 语言中可通过
qtukey(1-𝛼, k, Inf) / sqrt(2)计算”。其实就是在自由度 = infinity,样本数 = k ,的学生化极差分布 (Studentized Range) 中取 (1-⍺) 分位数的值,这个在源码中也有所体现。
函数源码
添加了博主注释的函数源码如下:
1 | |
函数用法
输入参数
描述:多个算法在不同数据集上的测试结果 (精度,F1值 …) 所构成的矩阵,例:

格式:一个 Array_like 的数组 (Numpy 数组和二维列表都可以),或者是 DataFrame 对象,(如果是 DataFrame ,则有更多的相关参数需要输入,详见官方文档)
返回值
描述:由算法两两对比产生的 P-value DataFrame矩阵,用于与 alpha 进行比较。例:
写在最后
上述推导均为博主根据函数写法所得,如有谬误欢迎指证,感激不尽!